PaddleOCR-VL: Baidu's most advanced ERNIE-powered model to date
Supporting 109 languages, it accurately recognizes text, tables, formulas, and charts, and still runs efficiently with minimal resources.
Loading AI tools...
What is PaddleOCR-VL
PaddleOCR-VL is a state-of-the-art vision-language model with ERNIE-powered intelligence for document parsing, accurately recognizing text, tables, formulas, and charts across 109 languages with efficient processing capabilities.
- Multilingual Document RecognitionProcess documents in 109 languages with exceptional accuracy using state-of-the-art neural networks and advanced language understanding algorithms.
- Intelligent Element ParsingExperience comprehensive document analysis with optimized ERNIE-powered pipeline and dynamic resolution processing for instant, accurate results.
- High-Precision OutputGenerate structured, AI-ready data with accurate text extraction, proper table recognition, and detailed formula reconstruction.
Key Features of PaddleOCR-VL
SOTA vision-language model for document parsing with 0.9B parameters, supporting 109 languages and efficient resource utilization.
109 Languages Support
Accurately recognizes text in 109 languages with state-of-the-art performance, handling diverse scripts and multilingual documents seamlessly.
Complex Element Recognition
Expertly identifies and extracts text, tables, formulas, and charts from documents with precision, converting visual content into structured data.
Resource-Efficient Design
Compact 0.9B parameter model with dynamic resolution processing, delivering exceptional performance while maintaining minimal computational requirements.
ERNIE-Powered Intelligence
Built on advanced ERNIE-4.5-0.3B language model with NaViT-style visual encoder, providing superior understanding of document context and layout.
Document Format Parsing
Handles diverse document types including handwritten texts, historical documents, and complex layouts with page-level and element-level accuracy.
Real-time Processing
Experience instant document analysis with cloud-based infrastructure, enabling fast and scalable OCR processing without local hardware limitations.
Wall of Love
If you enjoy using PaddleOCR-VL, please share your experience on Twitter with the hashtag
🚀 PaddleOCR-VL is here!
— PaddlePaddle (@PaddlePaddle) October 16, 2025
Introducing PaddleOCR-VL (0.9B) — the ultra-compact Vision-Language model that reaches SOTA accuracy across text, tables, formulas, charts & handwriting. Breaking the limits of document parsing!🌍
Powered by:
• NaViT dynamic vision encoder
• ERNIE… pic.twitter.com/il11kQ159a
Holy shit… Baidu just dropped the most efficient multimodal model ever.
— Robert Youssef (@rryssf_) October 17, 2025
It’s called PaddleOCR-VL a 0.9B parameter beast that outperforms GPT-4o, Gemini 2.5, and every doc-AI model on the planet.
This thing reads 109 languages, parses text, tables, formulas, charts, and still… pic.twitter.com/EQEDD1GOij
PaddleOCR VL🔥 0.9B Multilingual VLM by Baidu @PaddlePaddlehttps://t.co/M3bHaAnLDA
— Adina Yakup (@AdinaYakup) October 18, 2025
✨ Ultra-efficient NaViT + ERNIE-4.5 architecture
✨ Supports 109 languages 🤯
✨ Accurately recognizes text, tables, formulas & charts
✨ Fast inference and lightweight for deployment
🔥 Huge milestone! PaddleOCR-VL just hit #1 on Hugging Face Trending — only 20 hours after release! 🚀
— PaddlePaddle (@PaddlePaddle) October 17, 2025
Let’s keep pushing the boundaries of document intelligence — come and drop a ❤️ now!
A big thank you to our amazing community for the love & support!
👉 https://t.co/rvzdPHvtuo…
Pretty wild what 900M params can do - PaddleOCR VL 🔥
— Vaibhav (VB) Srivastav (@reach_vb) October 17, 2025
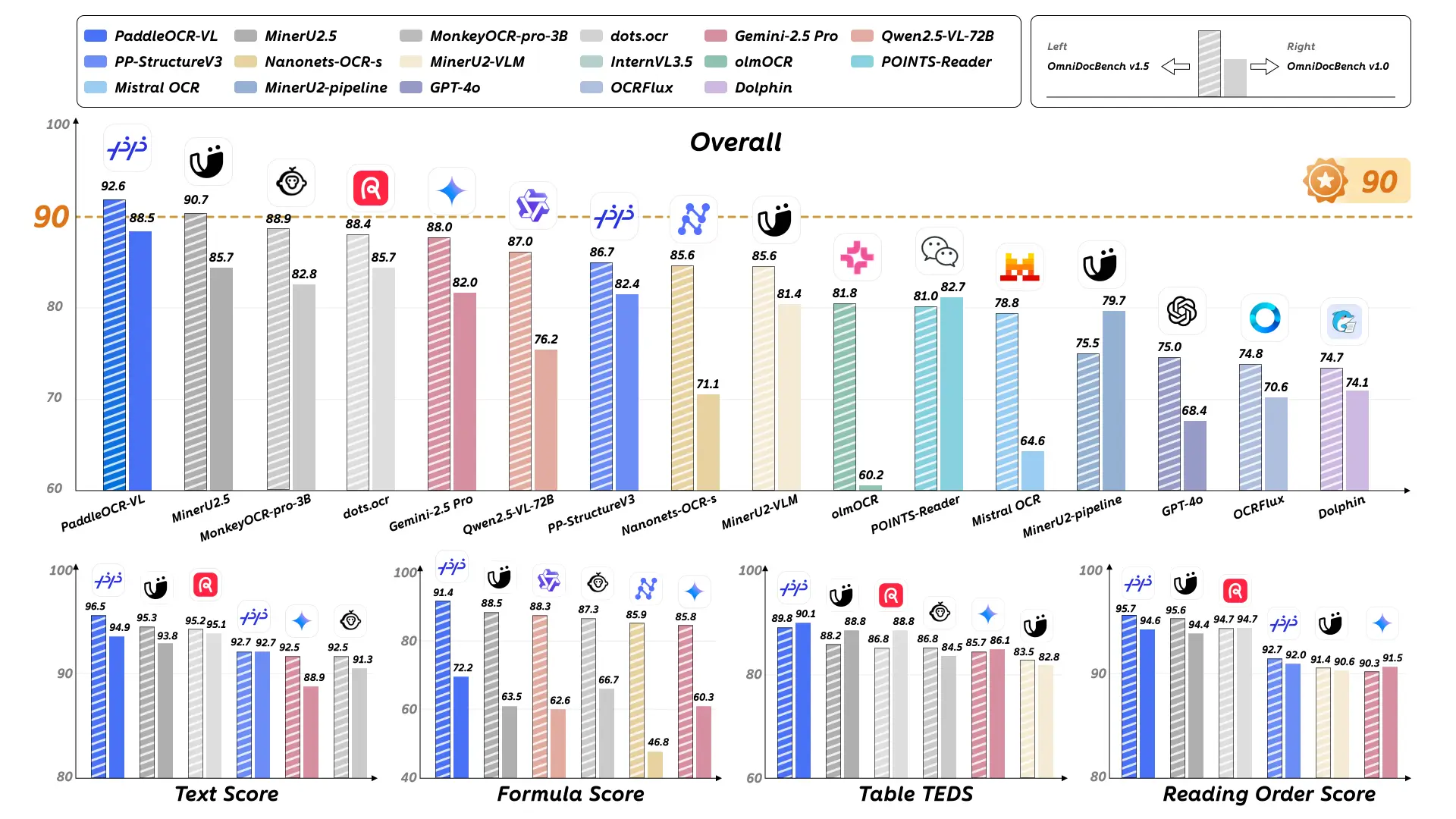
> SOTA on OmniDocBench v1.0 & v1.5 (text, tables, formulas, charts, reading order)
> Multilingual - 109 languages (Latin, Arabic, Cyrillic, Devanagari, Thai, etc)
> Handles handwriting, historical docs, noisy scans
> Supports…
PaddleOCR-VL-0.9B is mind blowing and it supports 109 languages!
— Tiezhen WANG (@Xianbao_QIAN) October 16, 2025
Check it out on HF demo: pic.twitter.com/870oWrQiwX
📚 Baidu (@Baidu_Inc) just launched and open-sourced a BRILLIANT model for document parsing - PaddleOCR-VL-0.9B.
— Rohan Paul (@rohanpaul_ai) October 17, 2025
Hugely boosting multilingual document parsing via a 0.9B Ultra-Compact Vision-Language Model built on ERNIE-4.5-0.3B.
It reaches #1 on OmniDocBench v1.5 with 90.67,… pic.twitter.com/2JnBL6e6jL
🚨 PaddleOCR-VL: Baidu’s New OCR Model Redefining Document Understanding
— Parul Gautam (@Parul_Gautam7) October 16, 2025
Baidu has officially launched and open-sourced PaddleOCR-VL-0.9B, Baidu’s most advanced ERNIE-powered model to date.
📊 Performance Highlights
• #1 globally on the OmniBenchDoc V1.5 leaderboard with a… pic.twitter.com/S07PlbEAw5
Document understanding just reached a new level.
— Manish Kumar Shah (@manishkumar_dev) October 16, 2025
Baidu has introduced PaddleOCR-VL-0.9B, a compact yet powerful vision-language model powered by ERNIE-4.5-0.3B.
Here’s why it stands out:
✅ #1 globally on the OmniBenchDoc V1.5 leaderboard, outperforming large multimodal models… pic.twitter.com/gGrfPMDZ17
Baidu just took document AI to the next level. 🚀
— RAVI KUMAR SAHU (@RAVIKUMARSAHU78) October 16, 2025
Their new PaddleOCR-VL-0.9B model might be built small, but it’s made for big things — powered by ERNIE-4.5-0.3B and designed to actually understand documents.
It recognizes structure, tables, formulas, and handwriting across… pic.twitter.com/ttzMjSXlVi
Frequently Asked Questions About PaddleOCR-VL
Have questions about document parsing and OCR? Find answers to common queries below.
What is PaddleOCR-VL and how does it work?
PaddleOCR-VL is Baidu's state-of-the-art vision-language model with 0.9B parameters, based on advanced ERNIE technology. It integrates a NaViT-style dynamic resolution visual encoder with ERNIE-4.5-0.3B language model for high-quality document parsing from text, tables, formulas, and charts.
What types of documents can I process with PaddleOCR-VL?
You can process diverse document types including handwritten texts, historical documents, complex layouts with tables and formulas, multilingual content, and various document formats. The model excels at recognizing text, tables, formulas, and charts with page-level and element-level accuracy across 109 languages.
Do I need to install anything to use PaddleOCR-VL?
No installation required. PaddleOCR-VL is a web-based tool that runs entirely in your browser. Simply access our online interface to start processing documents instantly without any software setup or configuration.
What languages does PaddleOCR-VL support?
PaddleOCR-VL supports 109 languages including Chinese, English, Japanese, Latin, Korean, Russian, Arabic, Hindi, Thai, and many others. It handles diverse script systems and language structures with state-of-the-art accuracy for multilingual document processing.
How accurate is PaddleOCR-VL's document recognition?
PaddleOCR-VL achieves state-of-the-art performance in both page-level and element-level document parsing, outperforming existing solutions. With its ERNIE-powered intelligence and dynamic resolution processing, it delivers exceptional accuracy for text extraction, table recognition, and formula reconstruction.
How long does it typically take to process a document?
With PaddleOCR-VL's optimized resource-efficient design and cloud-based processing, document analysis is nearly instantaneous. The 0.9B parameter model ensures rapid processing while maintaining minimal computational requirements for real-time feedback.